
不需要GPU,一分钟内即可在任何设备上部署大模型
 高性能、低功耗
高性能、低功耗
 多系统适配
多系统适配
 软硬协同优化
软硬协同优化
 感存算一体
感存算一体
不需要GPU,一分钟内即可在任何设备上部署大模型
高性能、低功耗
多系统适配
软硬协同优化
感存算一体
复刻人类大脑的运算与存储机制,重新定义AI效率边界

借鉴大脑定向激活逻辑,推理效率提升300%+,能源消耗降低60%,适配低功耗边缘设备。

复现“按需取数”模式,计算量降低50%,长文本处理速度提升数倍。

“点乘+加法”替代传统矩阵乘法,内存消耗降低70%,适配端侧CPU、GPU、NPU等芯片。
按5类核心维度评分:CPU速度、CPU存储占用、NPU速度、NPU存储占用、综合表现
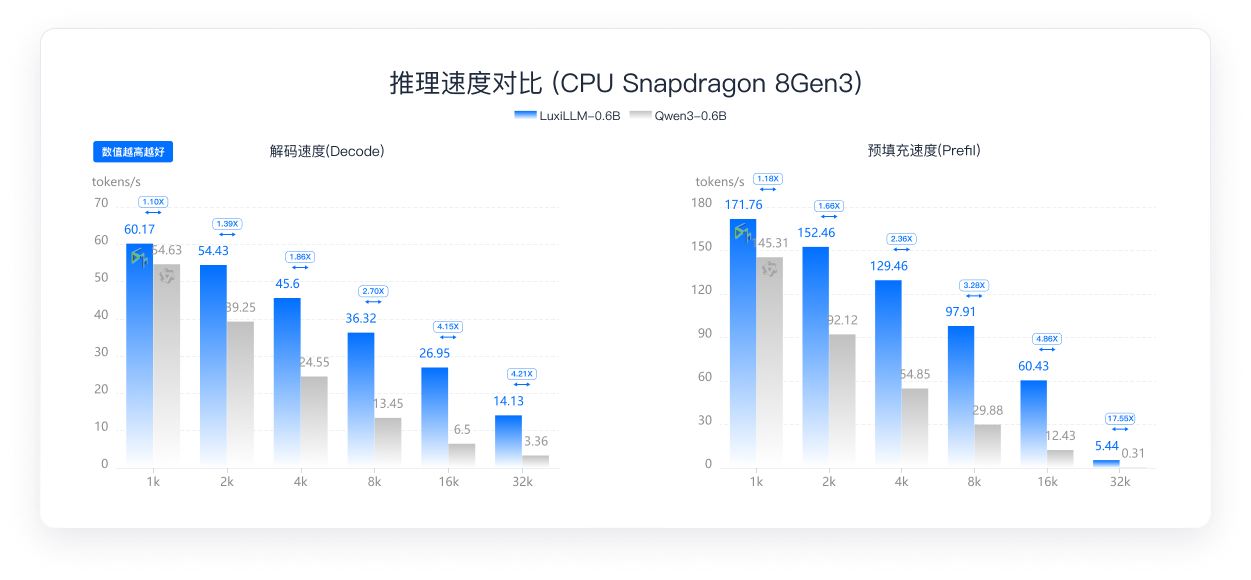
对比不同模型在CPU环境下的prefill/decode吞吐与响应延迟
解码与预填充双向领先,全面超越竞品
在CPU(Snapdragon 8 Gen 3)长上下文推理场景下,LuxiLLM-0.6B解码速度(Decode)快出竞品 4.21倍, 预填充速度(Prefill)快出竞品 4.86倍。 端侧推理更流畅、响应更迅速。
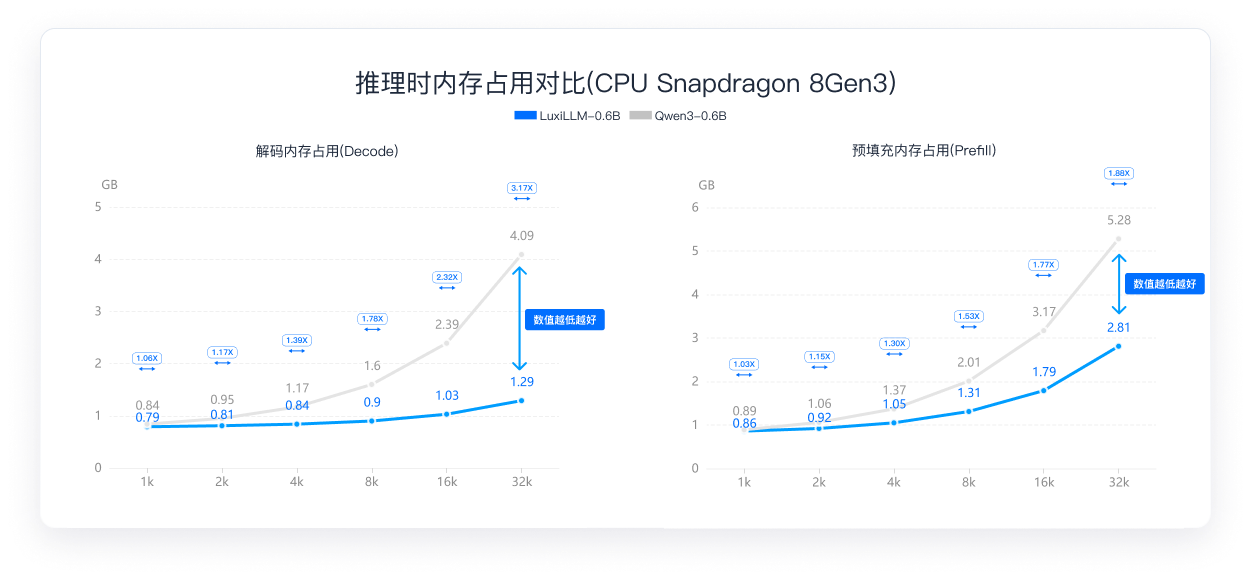
对CPU场景下模型权重、KV Cache与运行期内存占用规模
解码与预加载内存双优,长文本场景优势明显
在CPU(Snapdragon 8 Gen 3)上,LuxiLLM-0.6B在1k~32k全长度范围内,解码内存与预加载内存均低于Qwen3-0.6B。 尤其在32k超长文本下,解码内存节省 约68%, 预加载内存节省 约47%,让端侧设备也能轻松跑长上下文。
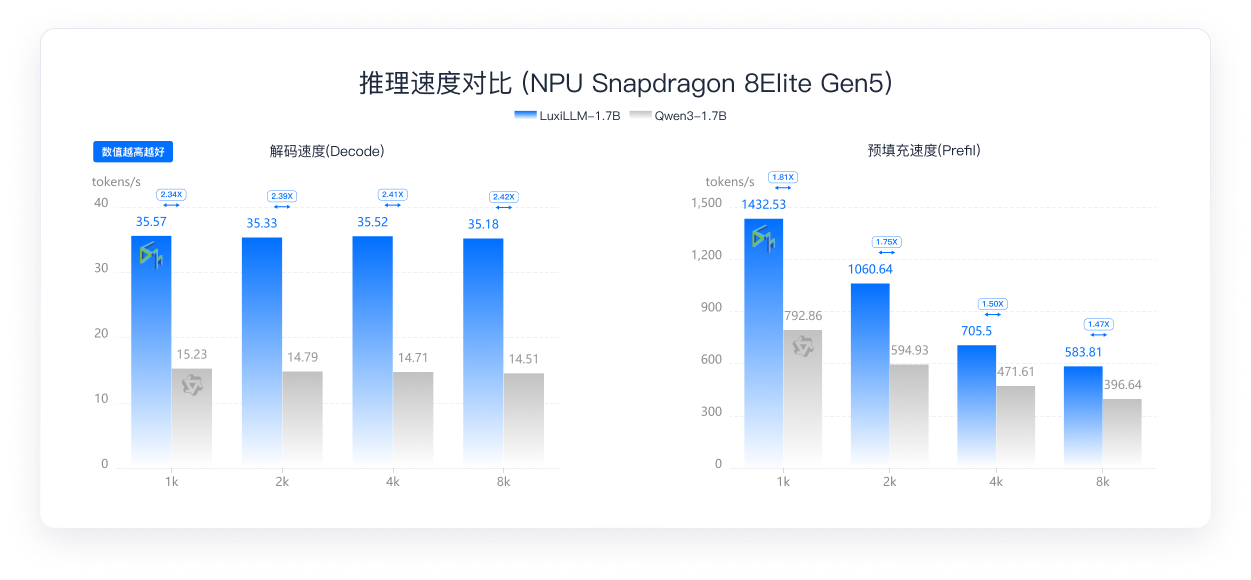
对比端侧NPU推理速度、批次处理能力与关键路径时延表现
解码快 2.4 倍,预填充快 1.8 倍
在 Snapdragon 8 Elite Gen 5 NPU 上,LuxiLLM-1.7B 展现出极致的推理效率。 长文本场景下,解码速度稳定为 Qwen3-1.7B 的 2.4 倍, 预填充速度达到 1.5~1.8 倍。 无论是实时对话还是长文档处理,都能实现无延迟响应。
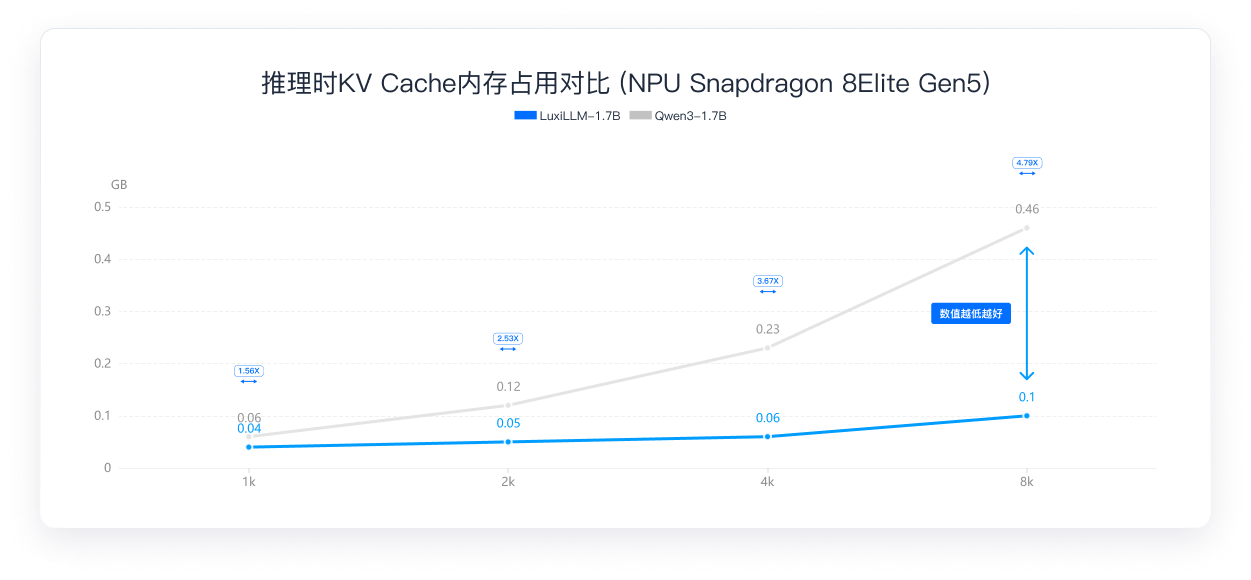
对比NPU侧模型编译后体积、缓存占用与部署空间需求
动态KV缓存内存大幅压缩,8k 长度仅占竞品五分之一
在 NPU(Snapdragon 8 Elite Gen 5)上,LuxiLLM-1.7B 通过底层存储与计算优化,显著降低了长文本推理时的 KV Cache 内存占用。 在处理 8k 长度(约上万字)文本时,动态内存仅约 0.09GB, 而竞品高达 0.45GB, 仅为竞品的 1/5, 为端侧部署释放了宝贵的内存空间。
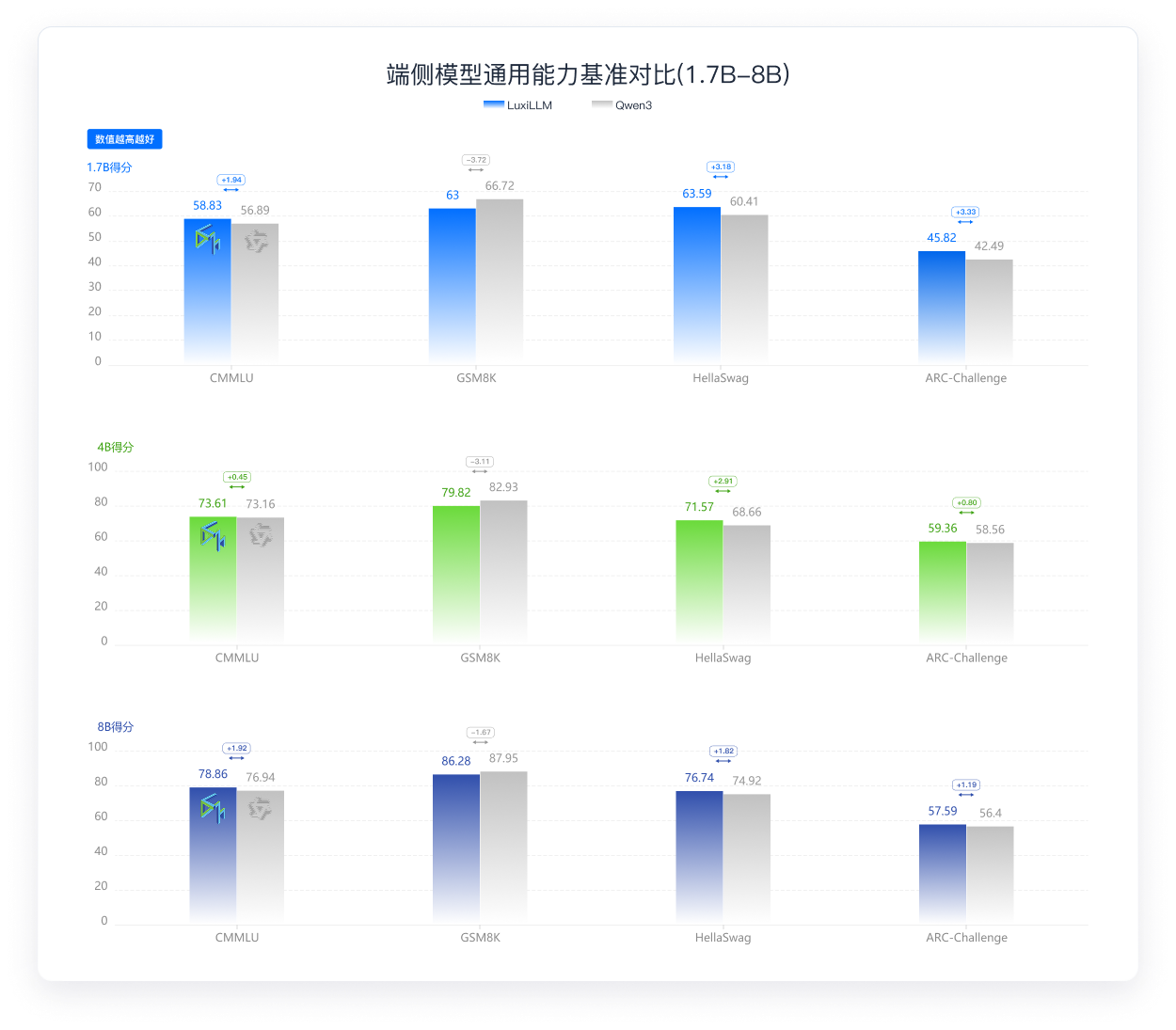
统一展示端侧模型能力的综合平衡表现
解码与预加载内存双优,长文本场景优势明显
在各个量级的模型中,LuxiLLM在科学与通用能力上均持平或优于Qwen3。LuxiLLM在保持极致推理效率与低内存占用的同时, 不牺牲模型效果 ,真正做到了“又快又好又省”。